Extract Setup in n8n
Setup
Select the 'Extract structured data from a document' action from the LlamaParse Platform node:
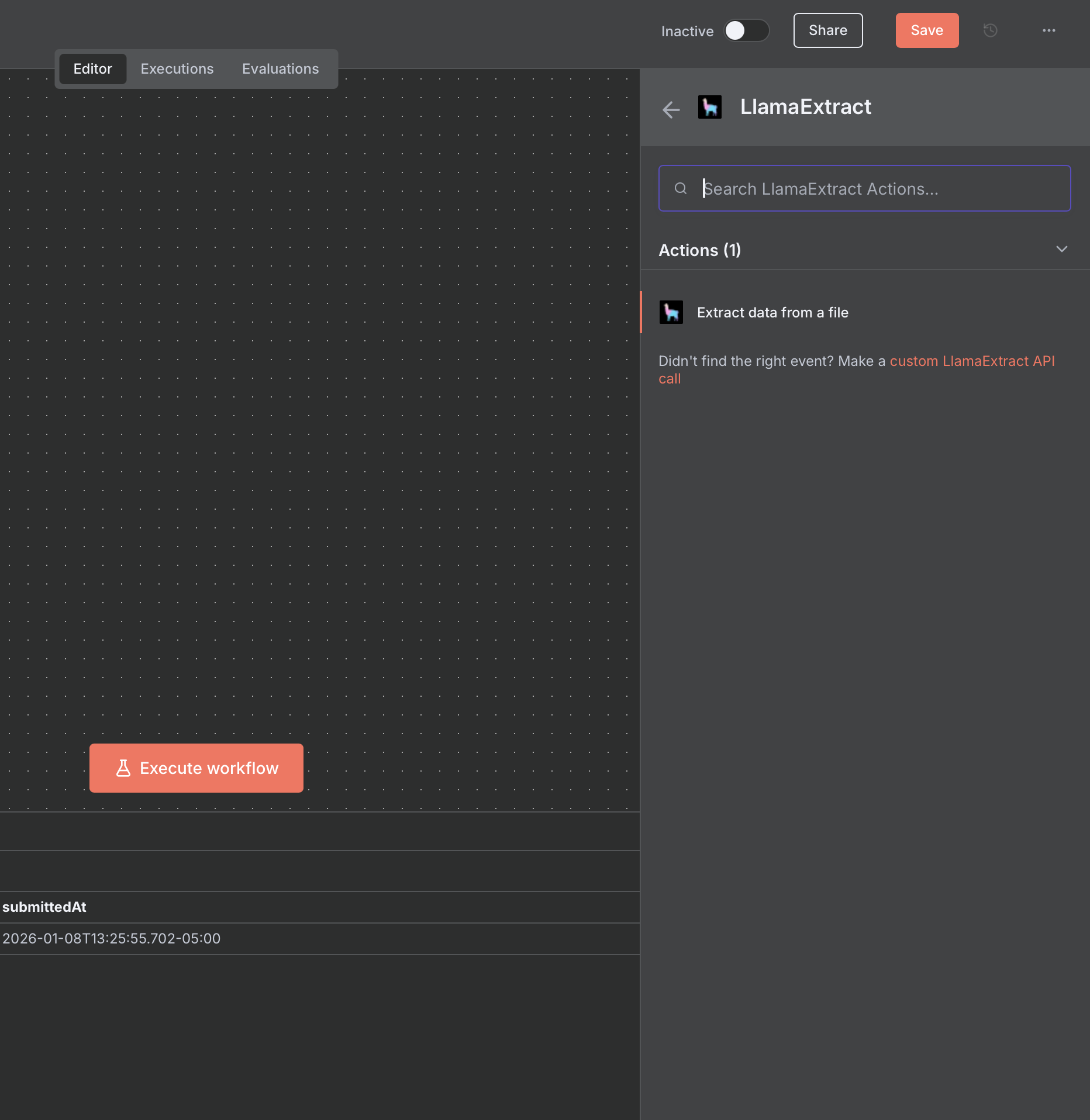
When setting up the action, define a JSON schema that the extracted data should follow, and the binary data of file:
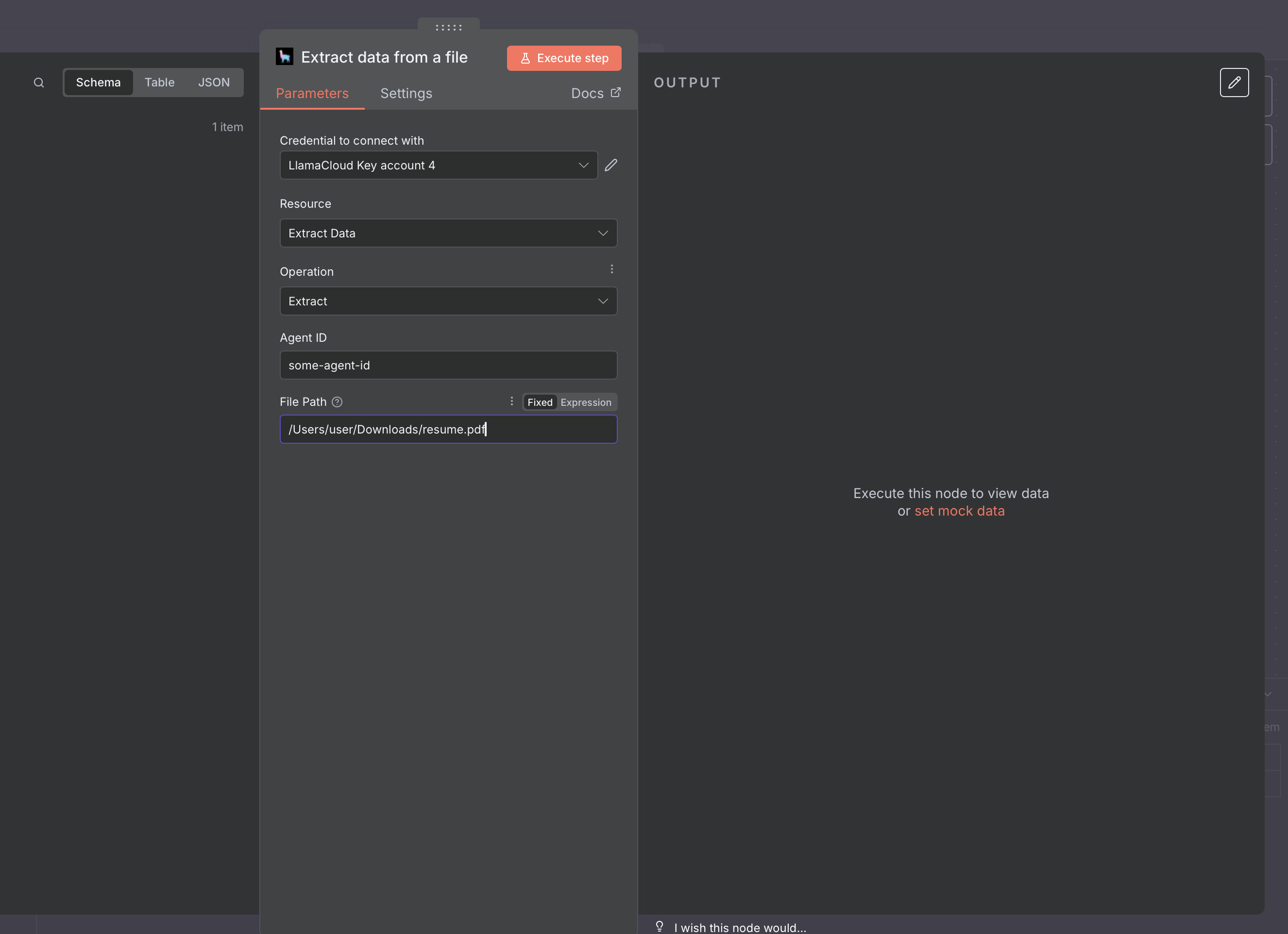
As for Parse, you can also set the node to receive inputs from other nodes, such as a webhook.